Database concepts you should know
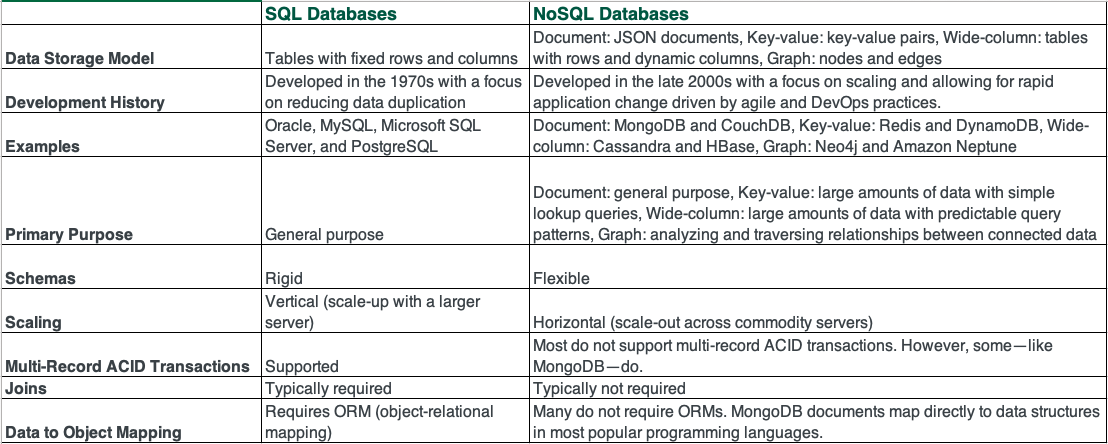
SQL vs. NoSQL
Benefits of NoSQL databases
NoSQL databases offer many benefits over relational databases. NoSQL databases have flexible data models, scale horizontally, have incredibly fast queries, and are easy for developers to work with.
- Flexible data models
NoSQL databases typically have very flexible schemas. A flexible schema allows you to easily make changes to your database as requirements change. You can iterate quickly and continuously integrate new application features to provide value to your users faster.
- Horizontal scaling
Most SQL databases require you to scale-up vertically (migrate to a larger, more expensive server) when you exceed the capacity requirements of your current server. Conversely, most NoSQL databases allow you to scale-out horizontally, meaning you can add cheaper, commodity servers whenever you need to.
- Fast queries
Queries in NoSQL databases can be faster than SQL databases. Why? Data in SQL databases is typically normalized, so queries for a single object or entity require you to join data from multiple tables. As your tables grow in size, the joins can become expensive. However, data in NoSQL databases is typically stored in a way that is optimized for queries. The rule of thumb when you use MongoDB is Data that is accessed together should be stored together. Queries typically do not require joins, so the queries are very fast.
- Easy for developers
Some NoSQL databases like MongoDB map their data structures to those of popular programming languages. This mapping allows developers to store their data in the same way that they use it in their application code. While it may seem like a trivial advantage, this mapping can allow developers to write less code, leading to faster development time and fewer bugs.
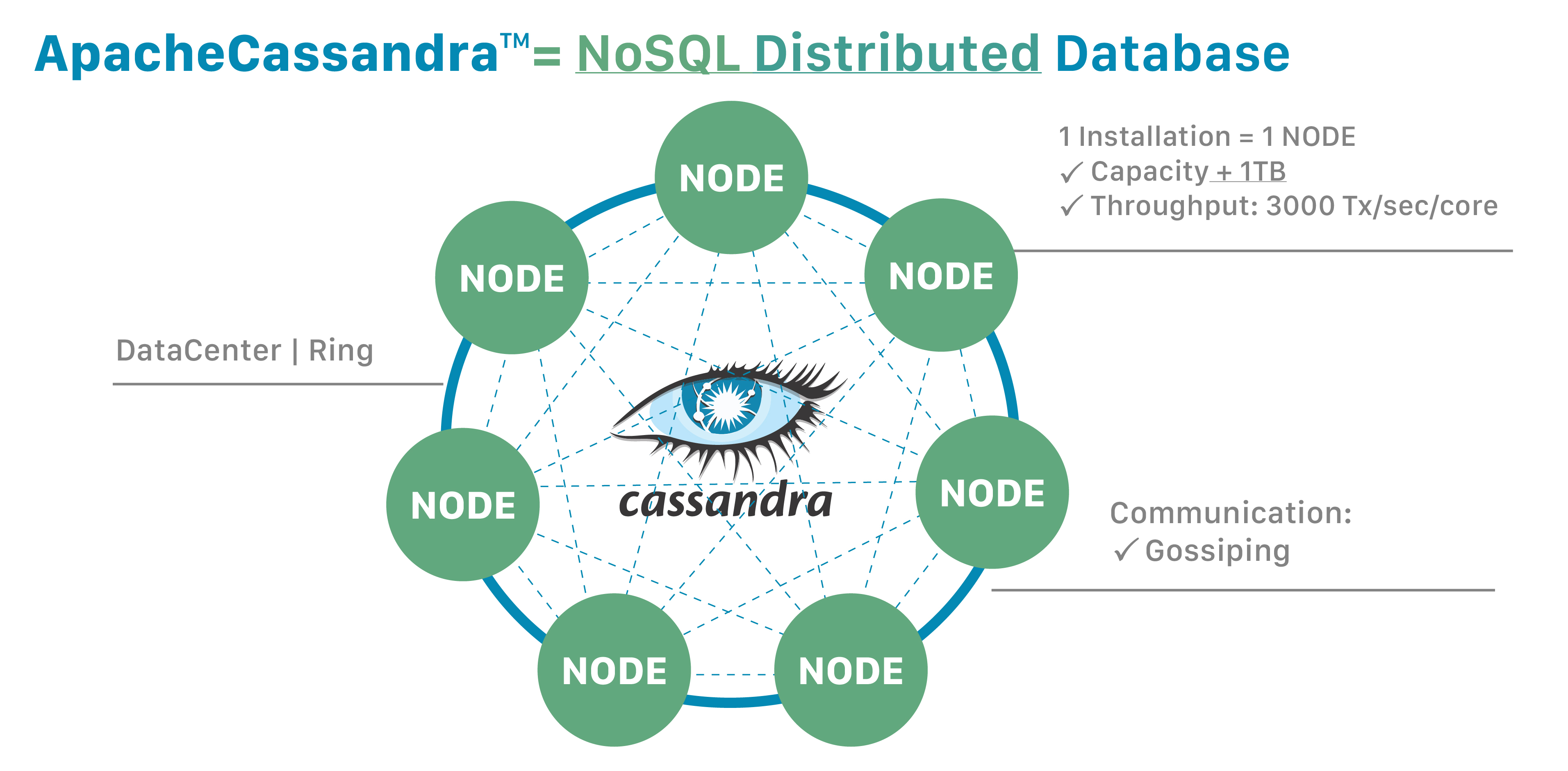
Apache Cassandra
Cassandra is a NoSQL distributed database. By design, NoSQL databases are lightweight, open-source, non-relational, and largely distributed. Counted among their strengths are horizontal scalability, distributed architectures, and a flexible approach to schema definition.
NoSQL databases enable rapid, ad-hoc organization and analysis of extremely high-volume, disparate data types. That’s become more important in recent years, with the advent of Big Data and the need to rapidly scale databases in the cloud. Cassandra is among the NoSQL databases that have addressed the constraints of previous data management technologies, such as SQL databases.
ACID and CAP theorem
A clear explanation can be referenced here
Database Index
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
An index is a copy of selected columns of data, from a table, that is designed to enable very efficient search. An index normally includes a “key” or direct link to the original row of data from which it was copied, to allow the complete row to be retrieved efficiently. Some databases extend the power of indexing by letting developers create indexes on column values that have been transformed by functions or expressions. For example, an index could be created on upper(last_name), which would only store the upper-case versions of the last_name field in the index. Another option sometimes supported is the use of partial indices, where index entries are created only for those records that satisfy some conditional expression. A further aspect of flexibility is to permit indexing on user-defined functions, as well as expressions formed from an assortment of built-in functions.
How are indexes created?
In a database, data is stored in rows which are organized into tables. Each row has a unique key which distinguishes it from all other rows and those keys are stored in an index for quick retrieval.
Since keys are stored in indexes, each time a new row with a unique key is added, the index is automatically updated. However, sometimes we need to be able to quickly lookup data that is not stored as a key. For example, we may need to quickly lookup customers by telephone number. It would not be a good idea to use a unique constraint because we can have multiple customers with the same phone number. In these cases, we can create our own indexes.
Sharding
Sharding is a method of splitting and storing a single logical dataset in multiple databases. By distributing the data among multiple machines, a cluster of database systems can store larger dataset and handle additional requests. Sharding is necessary if a dataset is too large to be stored in a single database. Moreover, many sharding strategies allow additional machines to be added. Sharding allows a database cluster to scale along with its data and traffic growth.
Sharding is also referred as horizontal partitioning. The distinction of horizontal vs vertical comes from the traditional tabular view of a database. A database can be split vertically — storing different tables & columns in a separate database, or horizontally — storing rows of a same table in multiple database nodes.
Amazon DynamoDB
Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-region replication, in-memory caching, and data export tools.
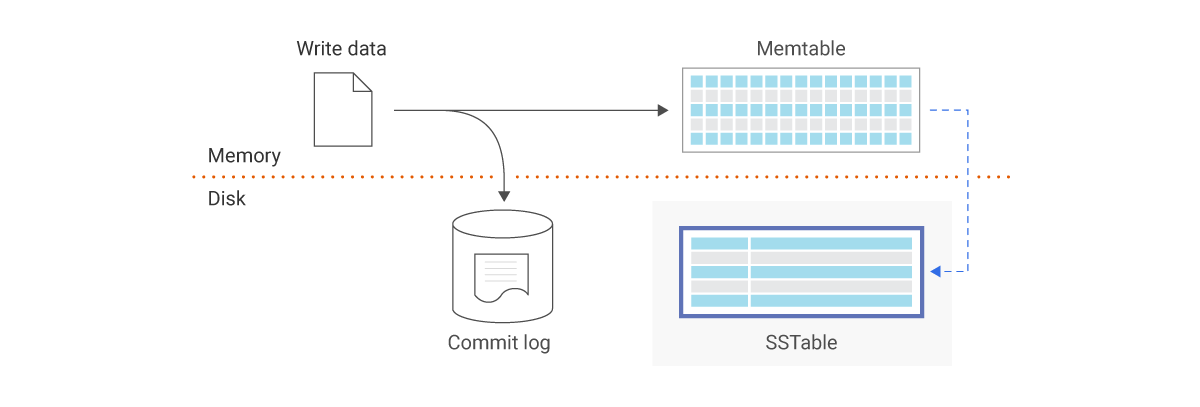
SSTable
Sorted Strings Table (SSTable) is a persistent file format used by Scylla, Apache Cassandra, and other NoSQL databases to take the in-memory data stored in memtables, order it for fast access, and store it on disk in a persistent, ordered, immutable set of files. Immutable means SSTables are never modified. They are later merged into new SSTables or deleted as data is updated.