Distributed system concepts you should know
This post contains basic explanations for concepts you should know related to distributed system.
API and REST API
Application Programming Interface, abbreviated as API, enables connection between computers or computer programs. It is a Software Interface that offers services to other software to enhance the required functionalities.
REST API is an API that follows a set of rules for an application and services to communicate with each other. As it is constrained to REST architecture, REST API is referred to as RESTful API. REST APIs provide a way of accessing web services in a flexible way without massive processing capabilities.
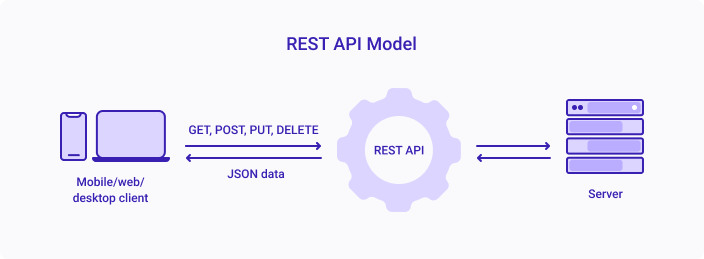
Below are the underlying rules of REST API:
- Statelessness - Systems aligning with the REST paradigm are bound to become stateless. For Client-Server communication, stateless constraint enforces servers to remain unaware of the client state and vice-versa. A constraint is applied by using resources instead of commands, and they are nouns of the web that describe any object, document, or thing to store/send to other resources.
- Cacheable - Cache helps servers to mitigate some constraints of statelessness. It is a critical factor that has improved the performance of modern web applications. Caching not only enhances the performance on the client-side but also scales significant results on the server-side. A well-established cache mechanism would drastically reduce the average response time of your server.
- Decoupled - REST is a distributed approach, where client and server applications are decoupled from each other. Irrespective of where the requests are initiated, the only information the client application knows is the Uniform Resource Identifier (URI) of the requested resource. A server application should pass requested data via HTTP but should not try modifying the client application.
- Layered - A Layered system makes a REST architecture scalable. With RESTful architecture, Client and Server applications are decoupled, so the calls and responses of REST APIs go through different layers. As REST API is layered, it should be designed such that neither Client nor Server identifies its communication with end applications or an intermediary.
Concurrency
Concurrency allows different parts of a program to run at the same time without affecting the outcome. For example, two people tried to withdraw $1000 from the same bank account in which only has $1500. Concurrency ensures the two people can’t overdraw the account.
There are three common tactics to ensure concurrency.
- Locking - A mechanism where a process has the right to update or write data. When a process acquires a lock, other processes can’t update or write.
- Atomicity - An atomic action is an action whose intermediate state can’t be seen by other processes or threads.
- Transaction - A sequence of atomic operations.
Message Queues
Queues are a component of service-based architectures. It accept client messages for delivery to a service, then hold the message until the service requests delivery.Once a queue has accepted a message, it provides a strong guarantee that the message will eventually be read and processed.Messages remain in the queue and available for delivery until the server confirms that it has finished with the message and deletes it.
Microservice Architecture
A microservice architecture – a variant of the service-oriented architecture (SOA) structural style – arranges an application as a collection of loosely-coupled services. In a microservices architecture, services are fine-grained and the protocols are lightweight. The goal is that teams can bring their services to life independent of others. Loose coupling reduces all types of dependencies and the complexities around it, as service developers do not need to care about the users of the service, they do not force their changes onto users of the service. Therefore it allows organizations developing software to grow fast, and big, as well as use off the shelf services easier. Communication requirements are less. But it comes at a cost to maintain the decoupling. Interfaces need to be designed carefully and treated as a public API. Techniques like having multiple interfaces on the same service, or multiple versions of the same service, to not break existing users code.
Proxy vs. Reverse Proxy
A proxy server, sometimes referred to as a forward proxy, is a server that routes traffic between client(s) and another system, usually external to the network. By doing so, it can regulate traffic according to preset policies, convert and mask client IP addresses, enforce security protocols, and block unknown traffic.
A reverse proxy is a type of proxy server. Unlike a traditional proxy server, which is used to protect clients, a reverse proxy is used to protect servers. A reverse proxy is a server that accepts a request from a client, forwards the request to another one of many other servers, and returns the results from the server that actually processed the request to the client as if the proxy server had processed the request itself. The client only communicates directly with the reverse proxy server and it does not know that some other server actually processed its request.
Horzontal vs. Vertical Scaling
Horizontal scaling (aka scaling out) refers to adding additional nodes or machines to your infrastructure to cope with new demands. If you are hosting an application on a server and find that it no longer has the capacity or capabilities to handle traffic, adding a server may be your solution.
While horizontal scaling refers to adding additional nodes, vertical scaling describes adding more power to your current machines. For instance, if your server requires more processing power, vertical scaling would mean upgrading the CPUs. You can also vertically scale the memory, storage, or network speed.
Distributed Cache
Caching means saving frequently accessed data in-memory, that is in RAM instead of the hard drive. Accessing data from RAM is always faster than accessing it from the hard drive.
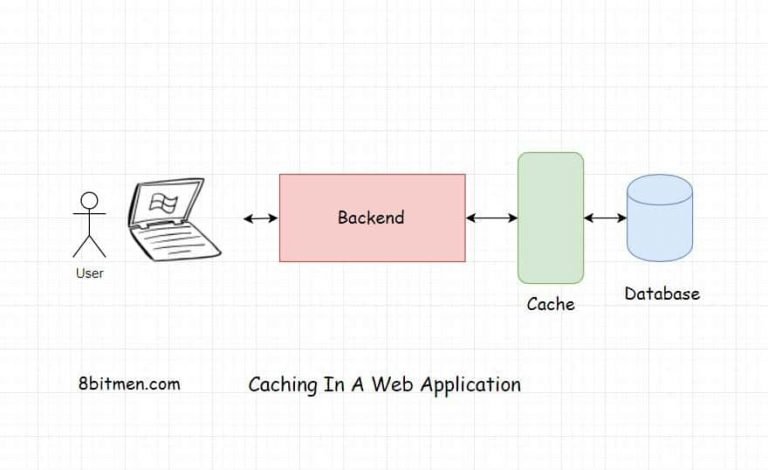
Caching serves the below-stated purposes in web applications.
- It reduces application latency by notches. Simply, due to the fact that it has all the frequently accessed data stored in RAM, it doesn’t has to talk to the hard drive when the user requests for the data. This makes the application response times faster.
- It intercepts all the user data requests before they go to the database. This averts the database bottleneck issue. The database is hit with comparatively lesser number of requests eventually making the application as a whole performant.
- Caching often comes in really handy in bringing the application running costs down.
Caching can be leveraged at every layer of the web application architecture be it a database, CDN, DNS etc.
A distributed cache is a cache which has its data spread across several nodes in a cluster also across several clusters across several data centres located around the globe.
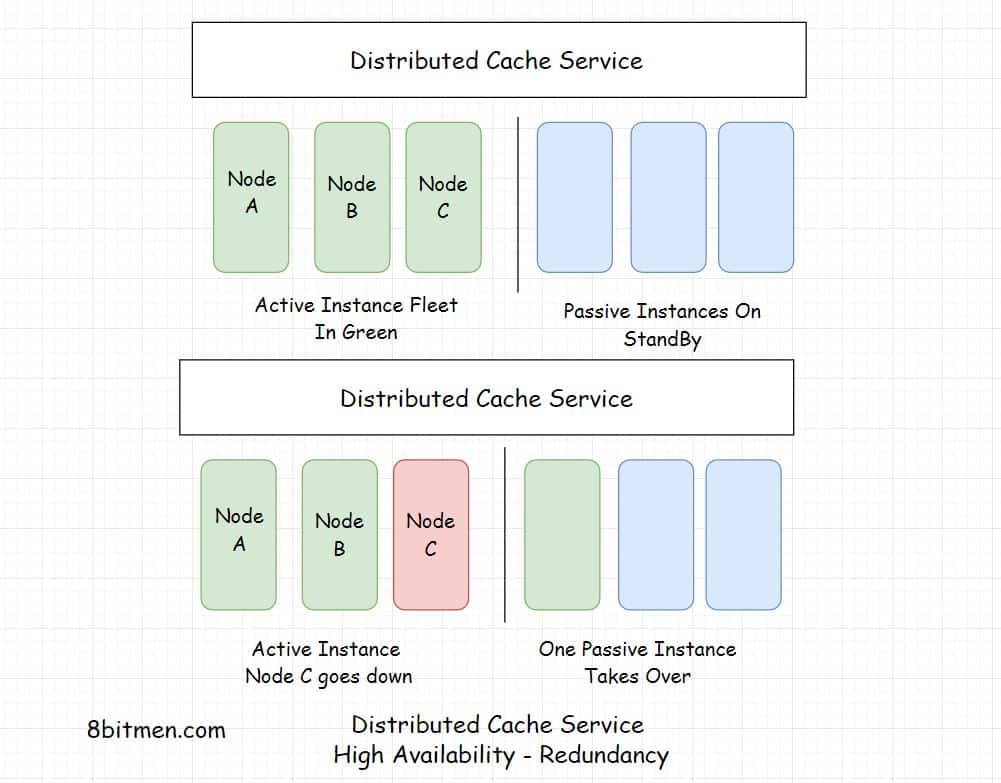
Being deployed on multiple nodes helps with the horizontal scalability, instances can be added on the fly as per the demand.
Distributed caching is being primarily used in the industry today, for having the potential to scale on demand & being highly available.
Scalability, High Availability, Fault-tolerance are crucial to the large scale services running online today. Businesses cannot afford to have their services go offline. Think about health services, stock markets, military. They have no scope for going down. They are distributed across multiple nodes with a pretty solid amount of redundancy.
Distributed cache, & not just cache, distributed systems are the preferred choice for cloud computing. Solely due to the ability to scale & being available.
Google Cloud uses Memcache for caching data on its public cloud platform. Redis is used by internet giants for caching, NoSQL datastore & several other use cases.
Content Delivery Network(CDN)
A content delivery network (CDN) refers to a geographically distributed group of servers which work together to provide fast delivery of Internet content.
A CDN allows for the quick transfer of assets needed for loading Internet content including HTML pages, javascript files, stylesheets, images, and videos. The popularity of CDN services continues to grow, and today the majority of web traffic is served through CDNs, including traffic from major sites like Facebook, Netflix, and Amazon.
Hadoop Distributed File System(HDFS)
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Map Reduce
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
A MapReduce program is composed of a map procedure, which performs filtering and sorting (such as sorting students by first name into queues, one queue for each name), and a reduce method, which performs a summary operation (such as counting the number of students in each queue, yielding name frequencies). The “MapReduce System” (also called “infrastructure” or “framework”) orchestrates the processing by marshalling the distributed servers, running the various tasks in parallel, managing all communications and data transfers between the various parts of the system, and providing for redundancy and fault tolerance.
Apache Zookeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them ,which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
ZooKeeper aims at distilling the essence of these different services into a very simple interface to a centralized coordination service. The service itself is distributed and highly reliable. Consensus, group management, and presence protocols will be implemented by the service so that the applications do not need to implement them on their own. Application specific uses of these will consist of a mixture of specific components of Zoo Keeper and application specific conventions. ZooKeeper Recipes shows how this simple service can be used to build much more powerful abstractions.
Apache Kafka
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Read-write quorum
Read-write quorums define two configurable parameters, R and W. R is the minimum number of nodes that must participate in a read operation, and W the minimum number of nodes that must participate in a write operation.
Read-Write Quorum Systems Made Practical - Michael Whittaker, Aleksey Charapko, Joseph M. Hellerstein, Heidi Howard, Ion Stoica
This paper reviews some concepts of the quorum systems, and it presents a concrete tool named “Quoracle” that explores the trade-offs of the read-write quorum systems.
Quoracle provides an alternative to the majority quorum systems that are widely adopted in distributed systems. The majority quorum can be defined as
\frac{n}{2} where n=number of nodes
In the case of a read-write quorum systems the majority is represented in a similar way:
r = w = \frac{n}{2} + 1
where r and w are the read and write quorums.
Gossip protocol
Gossip protocol is a communication protocol that allows state sharing in distributed systems. Most modern systems use this peer-to-peer protocol to disseminate information to all the members in a network or cluster.
This protocol is used in a decentralized system that does not have any central node to keep track of all nodes and know if a node is down or not.
Gathering state information by multicasting
So, how does a node know every other node’s current state in a decentralized distributed system?
The simplest way to do this is to have every node maintain heartbeats with every other node. Heartbeat is a periodic message sent to a central monitoring server or other servers in the system to show that it is alive and functioning. When a node goes down, it stops sending out heartbeats, and everyone else finds out immediately. But then O(N^2) messages get sent to every tick (N being the number of nodes), which is an expensive operation in any sizable cluster.
How the protocol works
The Gossip protocol is used to repair the problems caused by multicasting; it is a type of communication where a piece of information or gossip in this scenario, is sent from one or more nodes to a set of other nodes in a network. This is useful when a group of clients in the network require the same data at the same time. But there are many problems that occur during multicasting, if there are many nodes present at the recipient end, latency increases; the average time for a receiver to receive a multicast.
To get this multicast message or gossip across the desired targets in the group, the gossip protocol sends out the gossip periodically to random nodes in the network, once a random node receives the gossip, it is said to be infected due to the gossip. Now the random node that receives the gossip does the same thing as the sender, it sends multiple copies of the gossip to random targets. This process continues until the target nodes get the multicast. This process turns the infected nodes to uninfected nodes after sending the gossip out to random nodes.
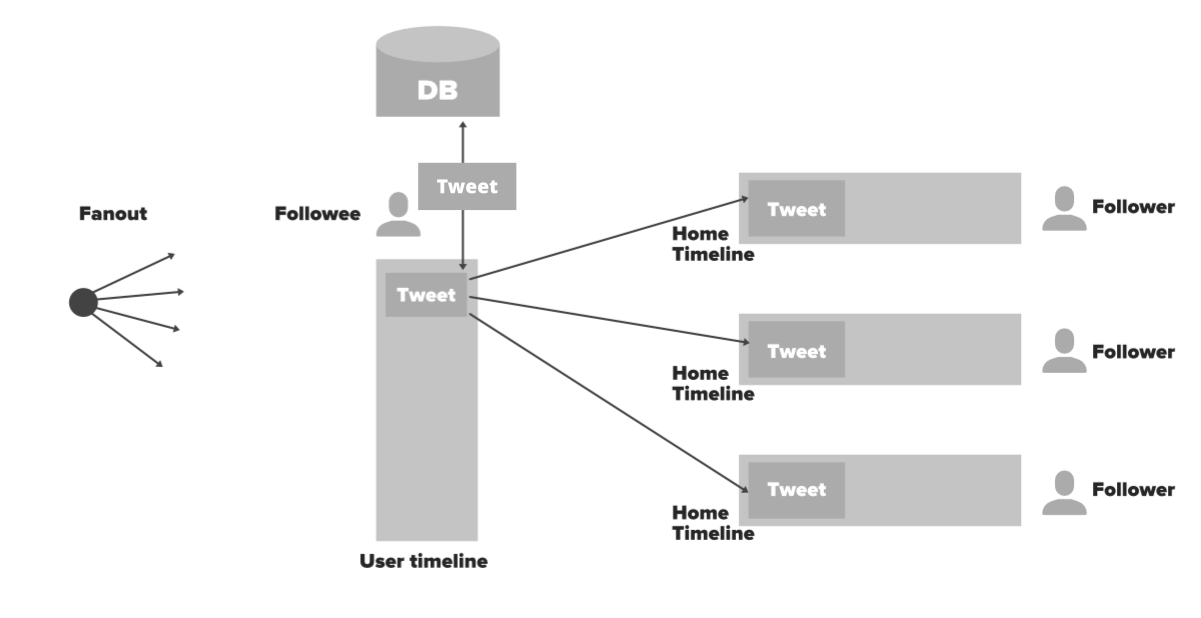
Fan Out
Let’s try to understand how fan out apporach works based on the system design of twitter here.
Fanout simply means spreading the data from a single point. Let’s see how to use it. Whenever a tweet is made by a user (Followee) do a lot of preprocessing and distribute the data into different users (followers) home timelines. In this process, you won’t have to make any database queries. You just need to go to the cache by user_id and access the home timeline data in Redis. So this process will be much faster and easier because it is an in-memory we get the list of tweets. Here is the complete flow of this approach.
- User X is followed by three people and this user has a cache called user timeline. X Tweeted something.
- Through Load Balancer tweet will flow into back-end servers.
- Server node will save tweet in DB/cache
- Server node will fetch all the users that follow User X from the cache.
- Server node will inject this tweet into in-memory timelines of his followers (fanout)
- All followers of User X will see the tweet of User X in their timeline. It will be refreshed and updated every time a user will visit on his/her timeline.
GUID and UUID
GUID (aka UUID) is an acronym for ‘Globally Unique Identifier’ (or ‘Universally Unique Identifier’). It is a 128-bit integer number used to identify resources. The term GUID is generally used by developers working with Microsoft technologies, while UUID is used everywhere else.