Scale a system to support millions of users
Start from single server
Building a large scale system is not one time effort, it should be an iterative process as the user workload increases. The journey could just start with single server and single user request.
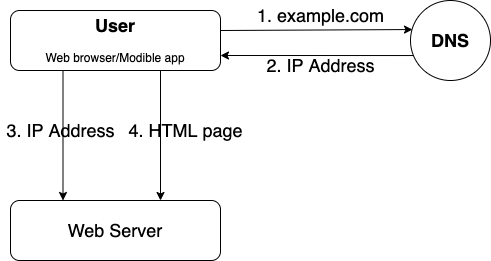
- User access a website through domain name, such as example.com
- IP address is returned to the browser or the mobile app.
- HTTP requests are sent to the web server.
- The web server returns the requested resources, such as a HTML page or JSON response.
Database
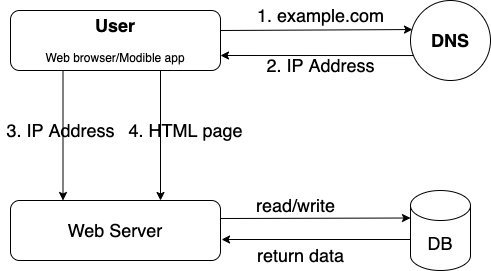
With the growth of the user base, we can separate the web server and database server to allow them scale independently.
SQL vs. NoSQL
We can choose between relational database and non-relational database.
Relational database is also called relational database management system(RDBMS) or SQL database. The popular relational databases are MySQL, Oracle database, MS-SQL database, PostgreSQL and so on. Relational database stores data in tables and rows. Join operations can be performed across different database tables.
Non-relational database is also called NoSQL database. The popular ones are MongoDB, CouchDB, Cassandra, HBase, Neo4j, Amazon DynamoDB and so on. They can be grouped into four categories: key-value stores, graph stores, column stores, and document stores. Generally, join operations are not supported in non-relational database.
Non-relational database might be the choice if:
- very low latency is required
- data is unstructured or not relational
- the data needs to be serialized and deserialied(JSON, XML, YAML, etc)
- massive amount of data needs to be stored
Vertical scaling vs. horizontal scaling
Vertical scaling, also called “scale up”, means adding more compute power(CPU/Memory), disk bandwidth, and network bandwidth to the servers. Vertical scaling is simple but it’s impossible to add unlimited resource to a single server. It doesn’t provide failover and redundancy and it may cause single point of failure.
Horizontal scaling, also called “scale out”, means adding more servers to the resouce pool. It’s suitable for large scale applications.
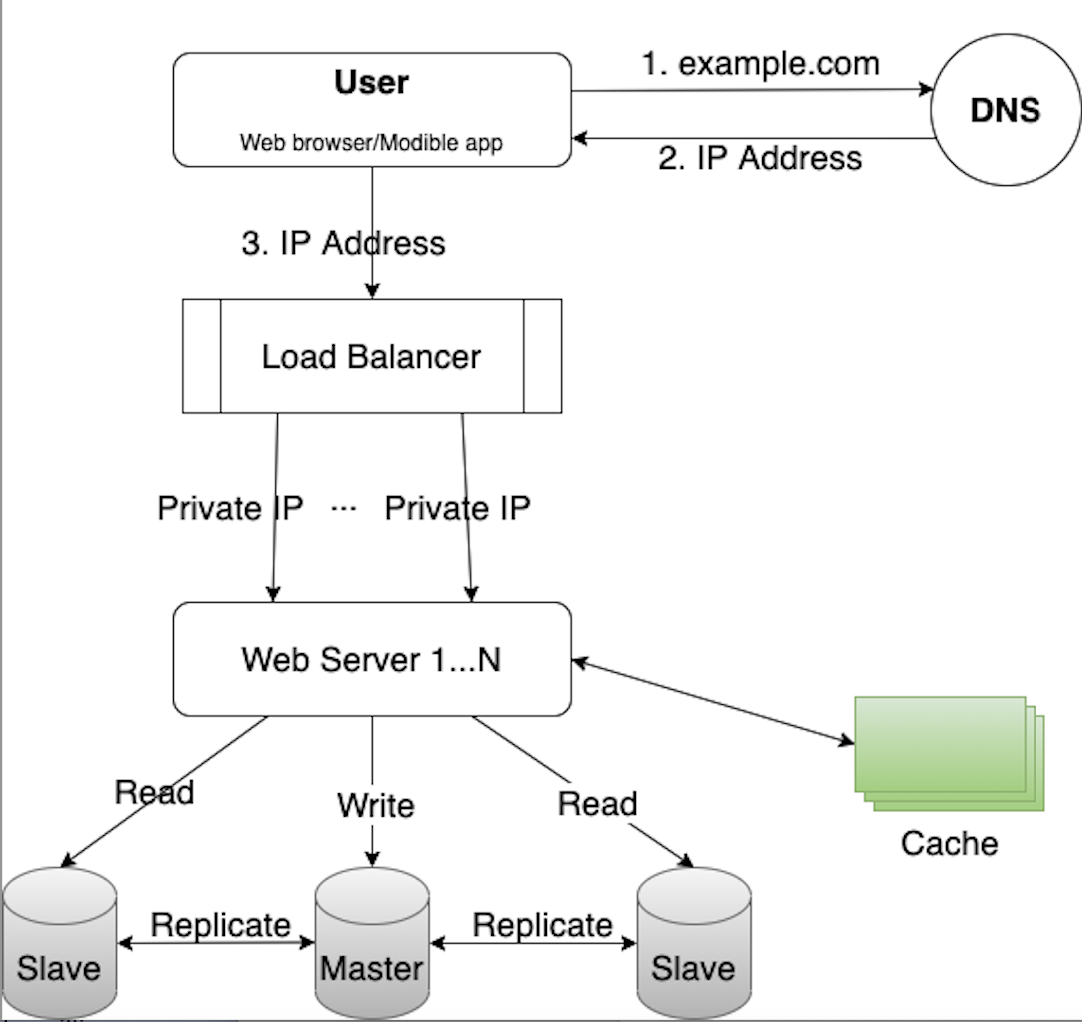
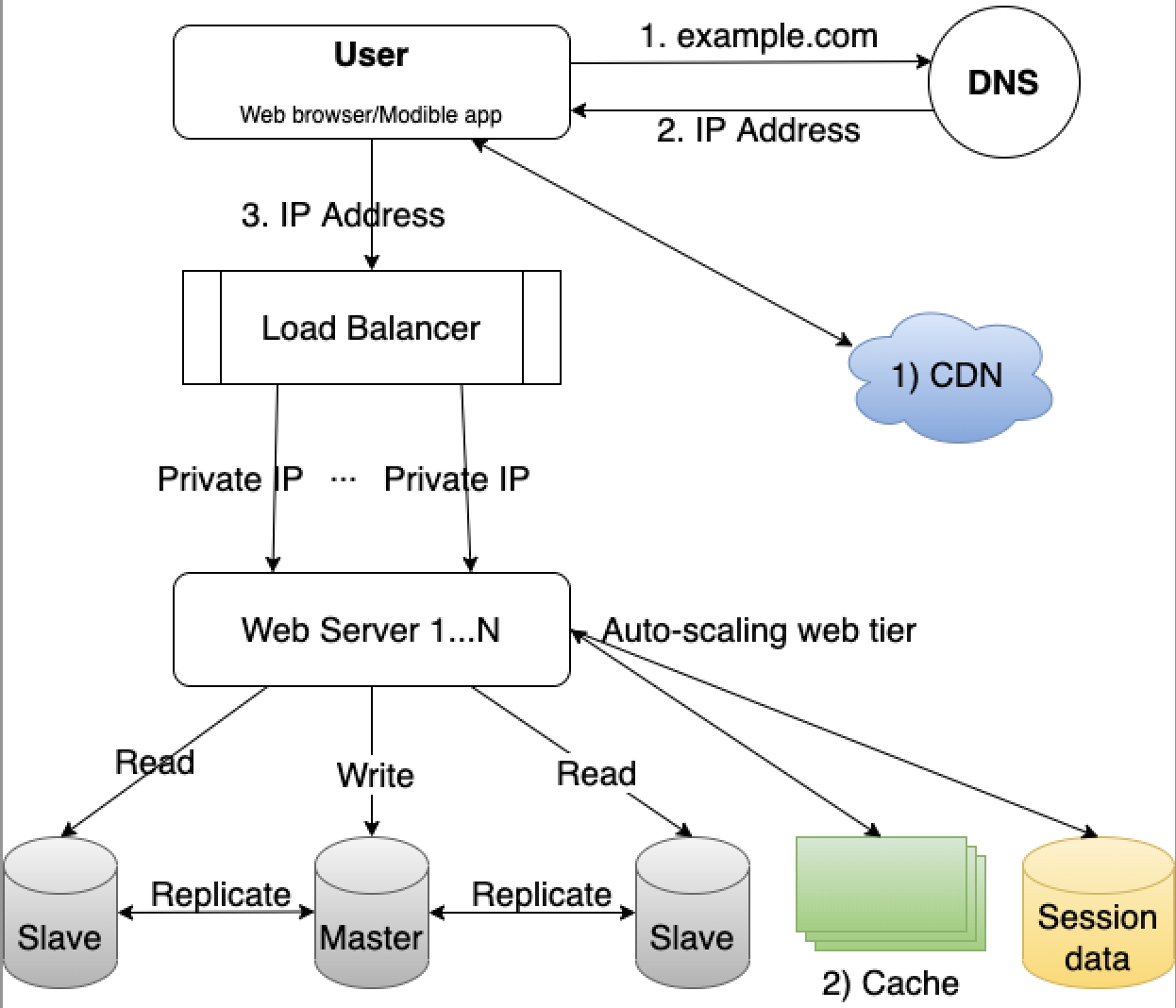
Load balancer
With the single server setup, users won’t be able to access the website if the web server goes offline. Users may experience slow response(high latency) or failed connection if there are too many user requests to the server simultaneously.
A load balancer can help evenly distribute incoming traffic among web servers.
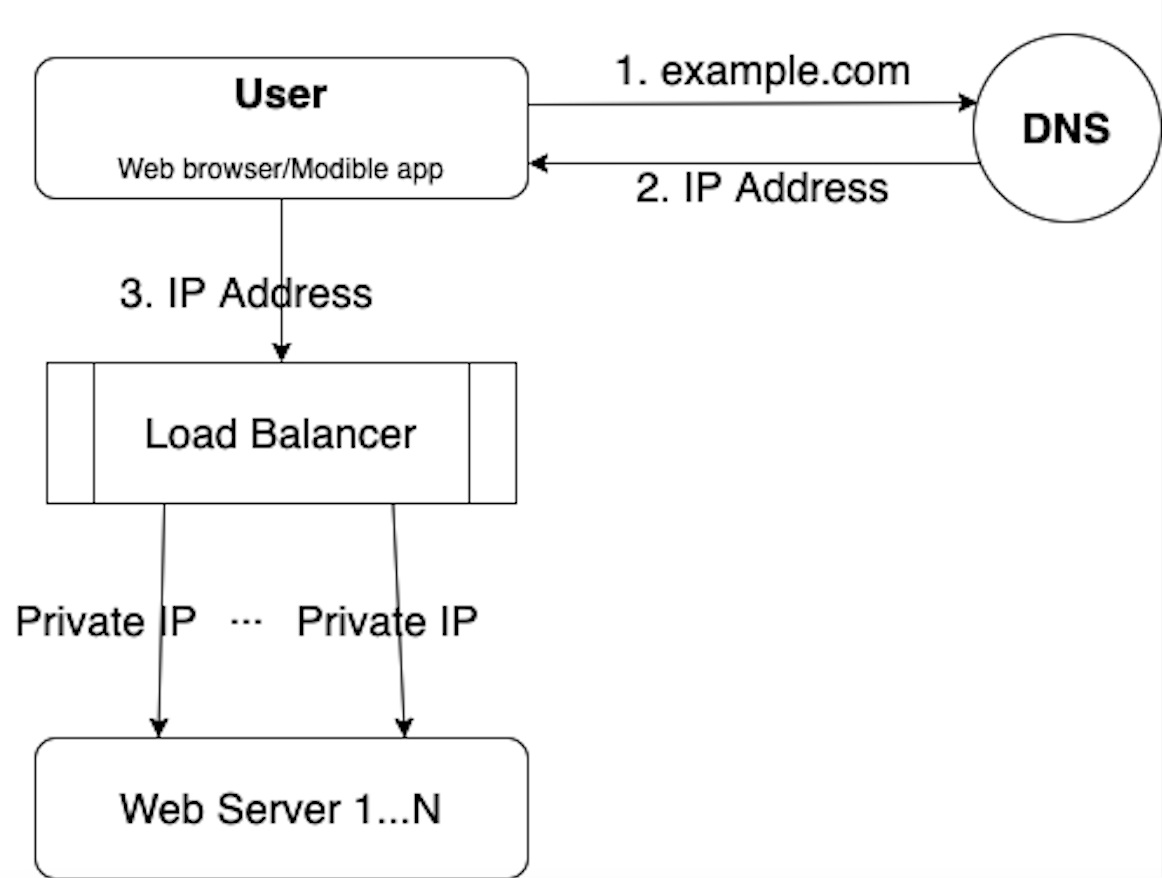
Users connect to the public IP of the load balancer. The web servers sitting behind the load balancer are unreachable directly by the users anymore. The private IPs can be used for communications between load balancer and web servers.
After the load balancer and more web servers are added, we improved the high availability of the web servers. For example, if web server 1 goes offline, the traffic can be routed to other web servers which are still healthy. As the website traffic grows rapidly, we can always add more web servers to scale and handle the incoming traffic.
Database replication
Now that we can scale the web tier as needed, how about the data tier? Database replication is a common technique to address the problems like failover and redundancy.
“Database replication can be used on many database management systems (DBMS), usually with a primary/replica relationship between the original and the copies.” Source
A master database generally supports write operations only. A slave database replicates data from master and only supports read operations.
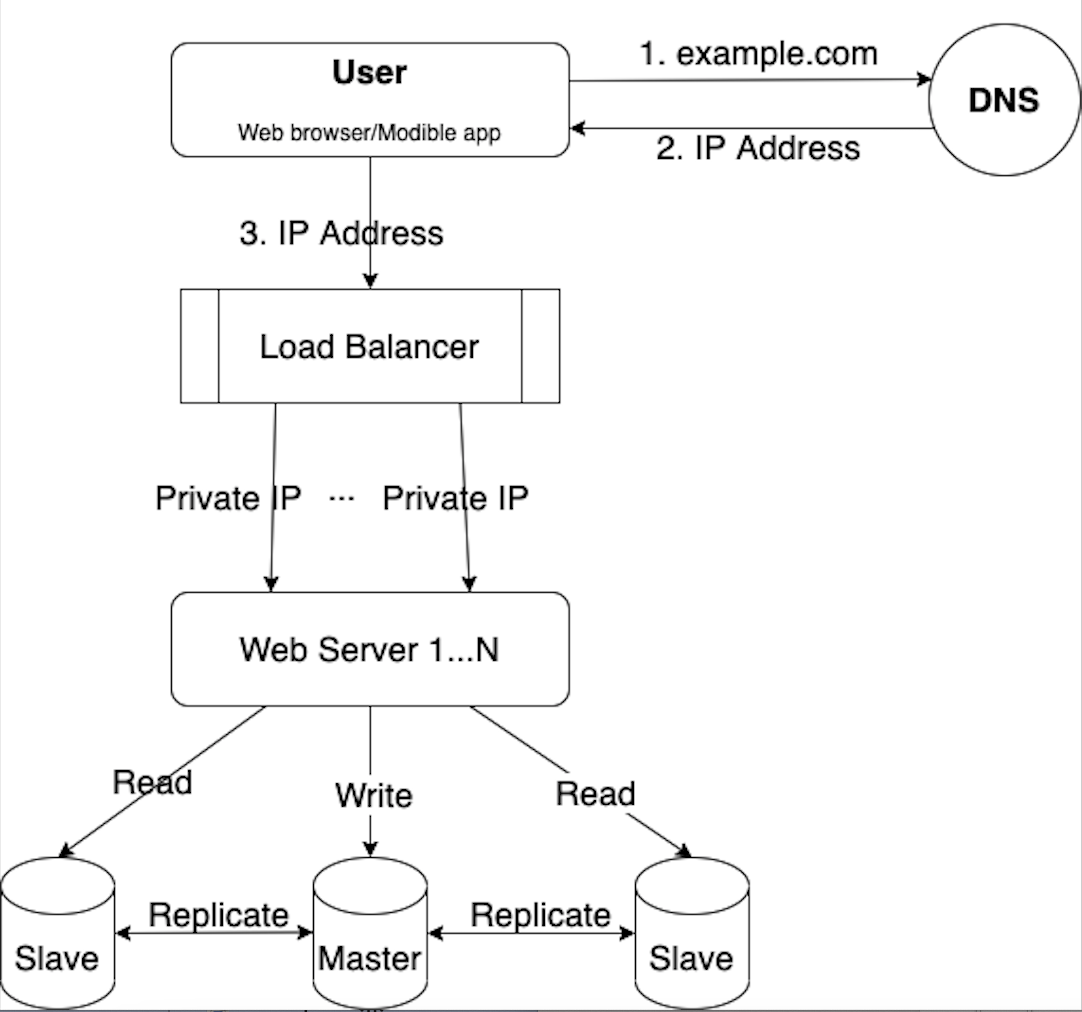
The master-slave model may not be the only method. We just use this model to learn about how to scale the database tier. We can achieve much better performance by spearating the write and read operations to master and slave databases. It also provides the data reliability in the case of natural disaster like earthquake. The data is highly available even if a database is offline.
- If the master database goes offline, a slave database will be promoted as the new master. A new slave database will replace the old one for data replication. Promoting a master is not that simple process because the data in slave database may not be up to date. The missing data have to be recovered by some recovery mechanism.
- If the slave databases are go offline, read operations can be directed to master database temporarily until a new slave database is in place.
Cache
After we have the design of scalable web and data tier, it’s time to improve the system performance like response time. Adding a cache layer can help serve the user requests more quickly.
- If data exists in cache, read data from cache
- If data doesn’t exist in cache, fetch data from database and save data to cache. Then the cached data are returned to web servers. This is so called read-through cache.
Here are some considerations for using a cache system:
- Consider using cache when the data is read frequently but write(modification) infrequently
- Use an expiration policy to reload the data from data store
- Use an eviction policy to add data to the already full cache. Least-recently-used(LRU) or First in First Out(FIFO)?
- Maintain the consistency between data store and cache. MemCache solution?
- Avoid single point of failure of a cache system
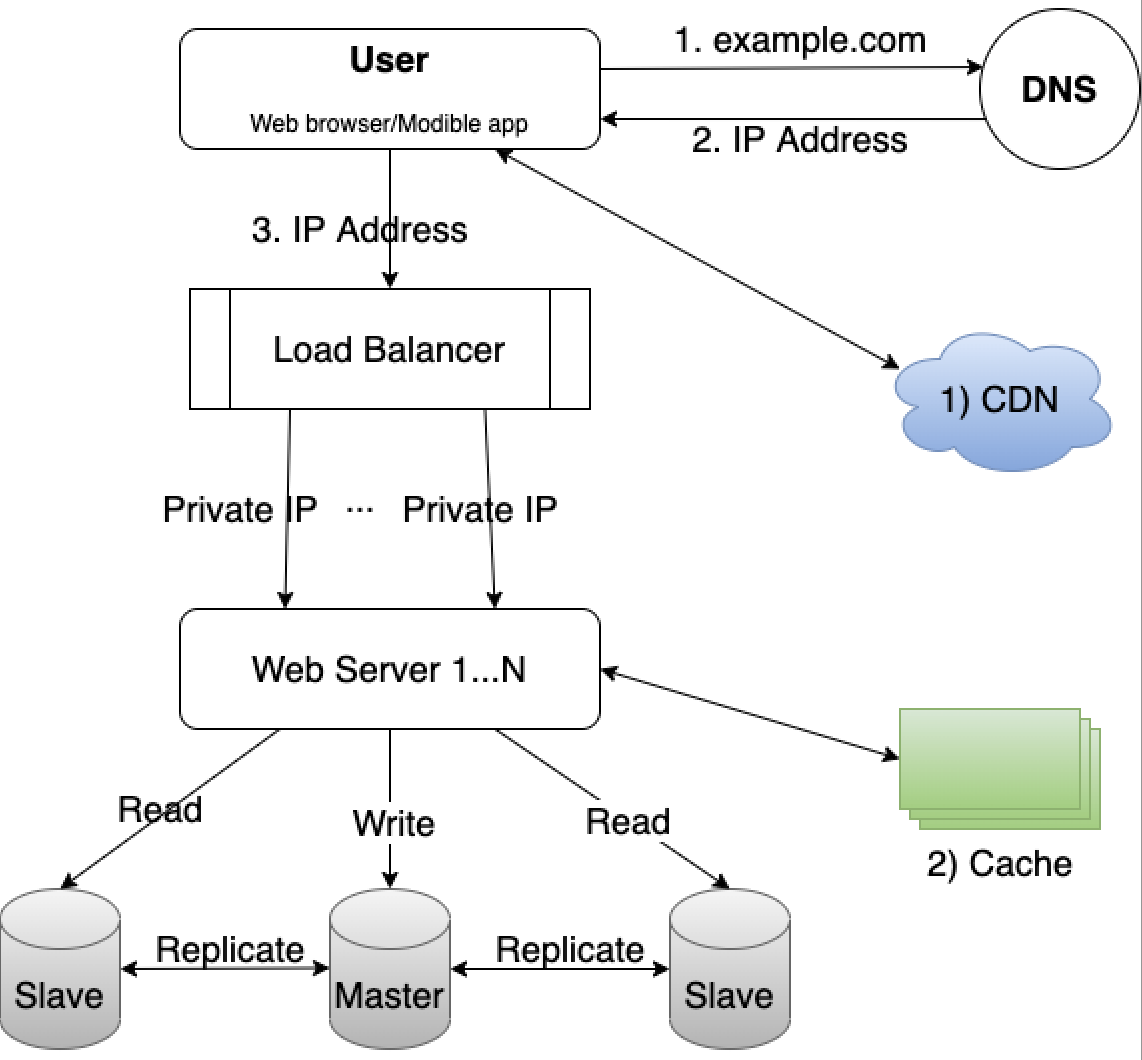
Content Delivery Network(CDN)
A CDN is a network of geographially dispersed servers used to deliver static content. CDN servers cache static content like images, videos, CSS, Javascript files, etc.
When a user visits a website, a CDN server closest to the user will deliver the static content. The website loads faster from a closer CDN server.
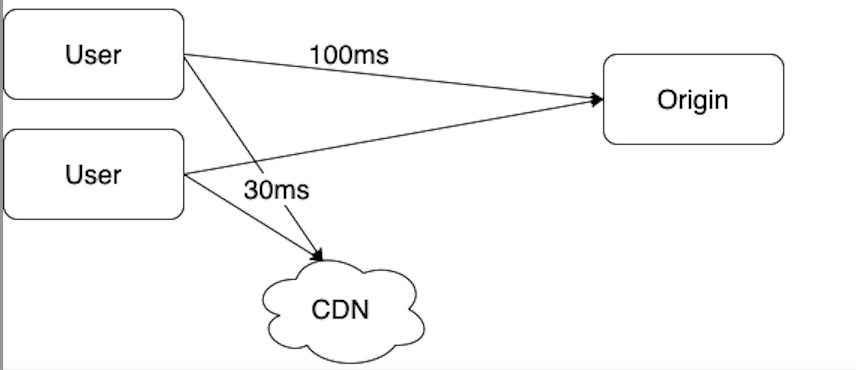
- If the content to be loaded is not in CDN, get it from the origin server and store it in CDN server.
- If the content is in CDN, return it from CDN.
Stateless web tier
In order to scale the web tier horizontally, we need to move the state(e.g. user session data) out of the web tier. A practice is to store the session data in the persistent storage such as SQL or NoSQL database. The web servers in the cluster can access the state data from the database. This is called stateless web tier.
In the stateless architecture, the HTTP requests from many users can be sent to any web servers. The session data will be fetched from a shared data store which is separated from web servers.
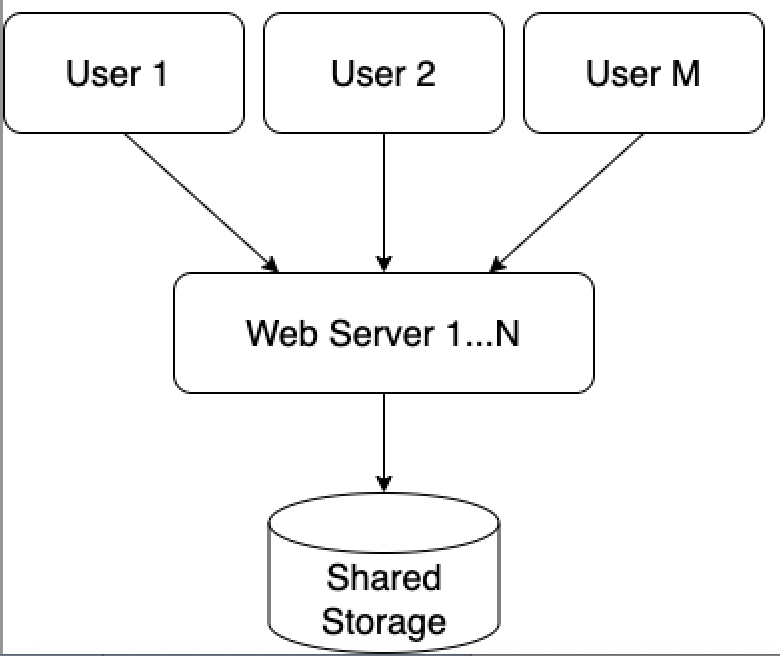
After the session data is stored out of web servers, auto-scaling of the web tier becomes a lot more easier.
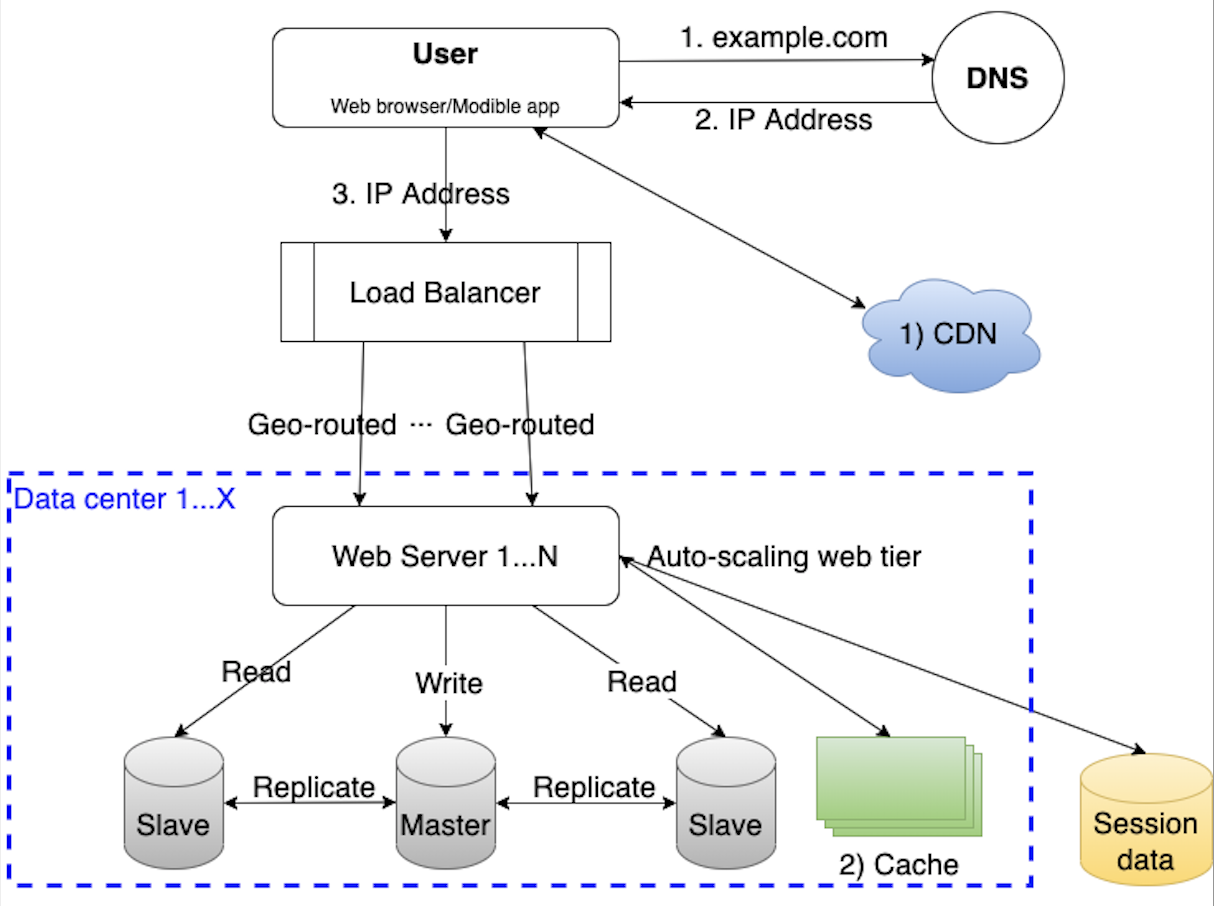
Data centers
As the website access grows internationally, supporting multiple data centers globally is crucial. In the event of any data center outage, the traffic can be directed to a healthy data center as well.
Message queue
To further scale the system, we can decouple the system components so that they can be scaled independently.
A message queue is a durable component, stored in memory, that supports asynchronous communication. It serves as a buffer and distributes asynchronous requests. Typically, a message queue has an input service, also called producers/publishers, to create message, and publish them to the message queue. The consumer services connect to the queue and process the messages asynchronously.

Logging, monitoring, automation
As the system scale for a very large business, it’s necessary to invest in the logging, monitoring and automation. These tools can help troubleshoot issues, understand system insight and system health, and improve productivity.
Database scaling
Vertical scaling and horizontal scaling are the two approaches for database scaling.
Vertical scaling, also known as scaling up, is to scale by adding more hardware components(CPU, Memory, Disk, Network) to the existing server. But it has a hardware limit and the cost can be high. Also there is risk of single point of failures.
Horizontal scaling, also known as sharding, is a practice of adding more database servers. Sharding separates large databases to smaller ones which are called shards. A hash function(e.g. user_id % n) can be used to determine which shard should be accessed. In this example of hash function, the user_id is the sharding key which is an important factor to consider when to implement a sharding strategy. The goal is to choose a key which can evenly distribute the data across shards.
With database sharding, it may introduce complexities and new challenges to the system.
- resharding data
- hotspot key
- join operations across database shards
Conclusion
Scaling a system is an iterative process. As the user requests increase and system scales, more fine-tuning and new strategies are needed. In summary, we can scale the system to support millions of users by addressing the following areas.
- Keep web tier stateless by storing session data out of web servers
- Have redundancy for each tier
- Cache data as much as possible to improve response time
- Build multiple data centers
- Use CDN to serve static content
- Sharding the data tier if needed
- Decouple the components to increase throughput(e.g. message queue)
- Add tools to improve ease of use