Lambda architecture in big data system
What is Lambda Architecture
When working with very large data sets, it can take a long time to run the sort of queries that clients need. These queries can’t be performed in real time, and often require algorithms such as MapReduce that operate in parallel across the entire data set. The results are then stored separately from the raw data and used for querying.
One drawback to this approach is that it introduces latency — if processing takes a few hours, a query may return results that are several hours old. Ideally, you would like to get some results in real time (perhaps with some loss of accuracy), and combine these results with the results from the batch analytics.
The lambda architecture, first proposed by Nathan Marz, addresses this problem by creating two paths for data flow. All data coming into the system goes through these two paths:
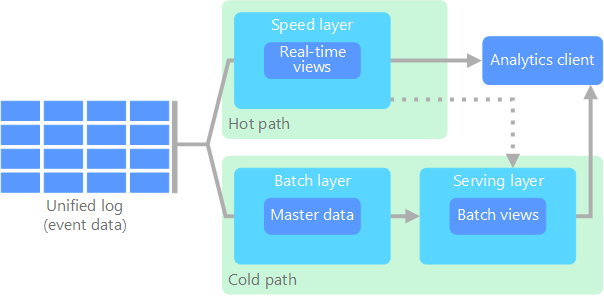
- A batch layer (cold path) stores all of the incoming data in its raw form and performs batch processing on the data. The result of this processing is stored as a batch view.
- A speed layer (hot path) analyzes data in real time. This layer is designed for low latency, at the expense of accuracy.
The batch layer feeds into a serving layer that indexes the batch view for efficient querying. The speed layer updates the serving layer with incremental updates based on the most recent data.
Data that flows into the hot path is constrained by latency requirements imposed by the speed layer, so that it can be processed as quickly as possible. Often, this requires a tradeoff of some level of accuracy in favor of data that is ready as quickly as possible. For example, consider an IoT scenario where a large number of temperature sensors are sending telemetry data. The speed layer may be used to process a sliding time window of the incoming data.
Data flowing into the cold path, on the other hand, is not subject to the same low latency requirements. This allows for high accuracy computation across large data sets, which can be very time intensive.
Eventually, the hot and cold paths converge at the analytics client application. If the client needs to display timely, yet potentially less accurate data in real time, it will acquire its result from the hot path. Otherwise, it will select results from the cold path to display less timely but more accurate data. In other words, the hot path has data for a relatively small window of time, after which the results can be updated with more accurate data from the cold path.
The raw data stored at the batch layer is immutable. Incoming data is always appended to the existing data, and the previous data is never overwritten. Any changes to the value of a particular datum are stored as a new timestamped event record. This allows for recomputation at any point in time across the history of the data collected. The ability to recompute the batch view from the original raw data is important, because it allows for new views to be created as the system evolves.
Batch Layer
New data comes continuously, as a feed to the data system. It gets fed to the batch layer and the speed layer simultaneously. It looks at all the data at once and eventually corrects the data in the stream layer. Here we can find lots of ETL and a traditional data warehouse. This layer is built using a predefined schedule, usually once or twice a day. The batch layer has two very important functions:
- To manage the master dataset
- To pre-compute the batch views.
Serving Layer
The outputs from the batch layer in the form of batch views and those coming from the speed layer in the form of near real-time views get forwarded to the serving. This layer indexes the batch views so that they can be queried in low-latency on an ad-hoc basis.
Speed Layer (Stream Layer)
This layer handles the data that are not already delivered in the batch view due to the latency of the batch layer. In addition, it only deals with recent data in order to provide a complete view of the data to the user by creating real-time views.
Benefits of lambda architectures
Here are the main benefits of lambda architectures:
- No Server Management – you do not have to install, maintain, or administer any software.
- Flexible Scaling – your application can be either automatically scaled or scaled by the adjustment of its capacity
- Automated High Availability – refers to the fact that serverless applications have already built-in availability and faults tolerance. It represents a guarantee that all requests will get a response about whether they were successful or not.
- Business Agility – React in real-time to changing business/market scenarios
Challenges with lambda architectures
- Complexity – lambda architectures can be highly complex. Administrators must typically maintain two separate code bases for batch and streaming layers, which can make debugging difficult.
Reference
- <BigData - Priciples and best practices of scalable real-time data systems>
- https://databricks.com/glossary/lambda-architecture
- https://docs.microsoft.com/en-us/azure/architecture/data-guide/big-data/