Kubernetes and Gluster performance
Kubernetes and Gluster Intro
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
Gluster is a scalable, distributed file system that aggregates disk storage resources from multiple servers into a single global namespace.
Gluster performance study
In this article, we will discuss the Gluster performance in a Docker container environment which is built on Kubernetes.
Configuration
We use three Redhat Linux servers to form a Kubernetes cluster in this study. A Kubernetes cluster that handles production traffic should have a minimum of three nodes.
We have three Docker containers(application instances) provisioned within the Kubernetes cluster. Each container instance has its own Gluster storage pool.
[node1:root]~> kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d14h
[node1:root]~> kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready master 6d14h v1.19.3
node2 Ready master 6d14h v1.19.3
node3 Ready master 6d14h v1.19.3
[node1:root]~> kubectl get pods --namespace ns-1
NAME READY STATUS RESTARTS AGE
container1 1/1 Running 0 6d14h
container2 1/1 Running 0 6d14h
container3 1/1 Running 0 6d14h
[...]
[node1:root]~> gluster pool list
UUID Hostname State
45d8ec04-4e7a-4442-bbb4-557256b864d6 10.10.1.3 Connected
875be270-ae69-45ea-b38e-2768b7c6ce05 10.10.1.4 Connected
f2696790-b305-4099-8dba-b31d23b0beac localhost Connected
Workload and performance
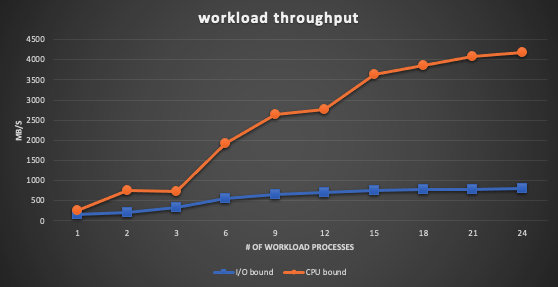
We keep increasing the number of workload processes across three container instances and measure the throughput in MB/s. For each workload process, it ingests data from multiple clients through 10GbE bonding network and writes the data to the mounted Gluster filesystem.
There are two kinds of workloads. One is very I/O intensive and the other is CPU bound.
Observation
- For the CPU bound workload, the performance scales very well.
- For the I/O bound workload, the performance does not scale when the number of workload processes increases.
Analysis
As we increase the number of workload processes, the workload can be distributed evenly across three instances(on three nodes). Thus, the CPU bandwidth from three nodes are available for the application computing.
Although the storage from three nodes are usable for three container instances, with the default disk allocation for Gluster filesystem, the I/O performance may not be optimal. It depends on how the disks are allocated to each Gluster filesystem bricks and how the bricks are assigned to the Gluster filesystems. Also, writing to remote disk would have worse performance due to network latency.
The following is the disk mapping to bricks which are used by one of the three Gluster filesystems. It shows four bricks are created on the same disk /dev/sde on the node 10.10.1.4. Obviously, the I/O performance could be degraded if multiple processes write on it.
brickSize(GB) device node
3200 /dev/sdd 10.10.1.2
3200 /dev/sde 10.10.1.2
3200 /dev/sdd 10.10.1.2
3200 /dev/sdd 10.10.1.2
3200 /dev/sdc 10.10.1.3
3200 /dev/sdc 10.10.1.3
3200 /dev/sdb 10.10.1.3
3200 /dev/sdb 10.10.1.3
3200 /dev/sde 10.10.1.4
3200 /dev/sde 10.10.1.4
3200 /dev/sde 10.10.1.4
3200 /dev/sde 10.10.1.4
Conclusion
From this case study, we had basic understanding on how the Gluster file system works with storage across multiple nodes. The default Gluster filesystem layout is not fit for all use cases. A custom storage layout would be needed to meet the performance requirement.